1 Johdanto
1990-luvulla on maailmalle avautunut uusi media tiedon tallentamiseen: internetin world-wide web (www). Se on http-protokollaa käyttävä, hallitsematon joukko miljoonia sähköisiä, pääasiassa html-kielellä kirjoitettuja dokumentteja, jotka on yhdistetty toisiinsa hyperlinkkien avulla. Www:n keksijän, Tim Berners-Leen mukaan (1994) sekä http että html on suunniteltu yksinkertaisiksi ja helposti omaksuttaviksi. Www-dokumentteja ei ole järjestetty tai luokiteltu mitenkään. Niillä on lukemattomia ylläpitäjiä ja ne siirtyvät satunnaisen tuntuisesti paikasta toiseen tai lakkaavat olemasta täysin varoittamatta. Www-sivuja yhdistävä hyperlinkkien joukko on rakentunut ilman minkäänlaista keskitettyä suunnittelua ja elää koko ajan. Lisäksi www-dokumentteihin viitataan edelleen niiden sijainnin perusteella, ei dokumentin nimellä.
Useissa tutkimuksissa on laskettu, että internetiin liitettyjen www-palvelinkoneiden määrä kasvoi yli kaksinkertaiseksi tammikuusta 1996 heinäkuuhun 1996. Suomessa kasvu on n. 10 % kuukaudessa eli suurin piirtein saman verran. Internetiin liitettyjä koneita on tällä hetkellä pelkästään Suomessa yhtä paljon kuin kuusi vuotta sitten oli koko maailmassa. (mm. Bray 1996, Gray 1996 ja Rissa & Järvinen 1996)
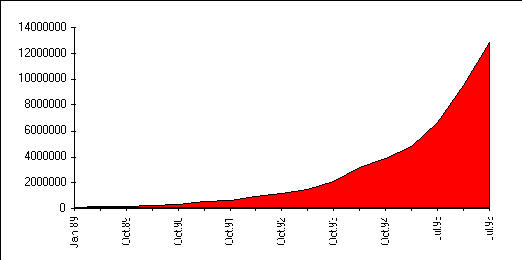
Kuva 1. Internetiin liitettyjen koneiden määrän kasvu. (Lottor 1996)
Heikkouksistaan huolimatta sekä suurelta osin helppoutensa ja yksinkertaisuutensa ansiosta www on saavuttanut viime vuosina suuren suosion ja sisältää nykyään jo varsin merkittävän määrän tietoa. Osa tästä tiedosta on sellaista, mitä ei mistään muualta löydy. Perinteiset tiedonhakumenetelmät eivät www:hen kuitenkaan päde. Tämä herättää käyttäjässä ainakin seuraavia kysymyksiä:
- Miten löydän etsimäni tiedon helposti ja nopeasti?
- Mistä tiedän, onko löytämäni tieto luotettava?
- Mistä tiedän, onko löytämäni tieto ajankohtainen?
- Mistä voin kysyä lisätietoja www:stä löytämälleni tiedolle?
- Miten karsin pois "turhan" tiedon ja tutustun vain olennaiseen?
Rissa & Järvinen Oy:n (1996) tekemän tutkimuksen mukaan yli puolet suomalaisista web-käyttäjistä kokee ongelmaksi tiedon löytämisen vaikeuden ja lähes yhtä moni osoiterekisterin puutteen. On selvää, että ratkaisuksi ei kelpaa kaikkien www-dokumenttien läpi lukeminen, vaan tiedonhaku on automatisoitava tavalla tai toisella. Tällä hetkellä tämä tarkoittaa ns. hakumoottoreita sekä agenttiohjelmia, jotka tekevät työn käyttäjän puolesta. Tällaisia ohjelmia on olemassa lukuisia ja toteutustapoja yhtä monta.
Tässä tutkimuksessa vertailen joitakin suosituimpia ns. hakurobotteja sekä niiden jatkeeksi tehtyjä hakuohjelmia. Näiden välissä on useimmiten myös jonkinlainen indeksointiohjelma, joka kuitenkin yleensä on integroitu hakurobottiin. Indeksointiohjelmien ominaisuuksiin en puutu. Myöskään en ota vertailuun mukaan suoraan www-selainohjelmasta käytettäväksi tarkoitettuja hakurobotteja kuten De Bran (1994) esittelemä Fish-search, joiden merkitys käytännössä on varsin vähäinen. Tarkoitus on löytää www-hakupalvelu, joka tietyillä kriteereillä laskettuna osoittautuu parhaaksi - sellainen, jonka hakurobottiohjelma ei aiheuta haittaa muille ja joka on loppukäyttäjälle mahdollisimman hyödyllinen. Samalla etsitään tavallisimmat virheet, joita hakuohjelmien tekijät ovat tehneet ja joita vastaisuudessa on syytä välttää. Tutkimusote on siis lähinnä kenttäkoe vaikka siinä onkin joitakin kontrolloidun kokeen piirteitä. Kaikki tekijät eivät kuitenkaan ole tutkijan kontrollissa.
Aihetta on viime vuosina tutkittu maailmalla aika paljonkin. Yksi tuoreimmista suomalaisista on Tuomelan (1996) Oulun yliopistossa tekemä. Barry (1996) luettelee yli kymmenen tutkimuksen tärkeimmät tulokset sekä linkit tutkimusten kotisivuille. Www-tiedonhaku kuitenkin uudistuu koko ajan ja käytännössä lähes kaikki kahta, kolmea kuukautta vanhemmat tutkimukset ovat enemmän tai vähemmän vanhentuneita. Lisäksi kaikki edellä mainitut tutkimukset keskittyvät vain hakukoneiden toimivuuteen ja kattavuuteen eikä mikään niistä tarkastele itse hakurobotin toimintaa, sen tehokkuutta ja kurinalaisuutta. Tässä tutkimuksessa tutkin sekä hakuohjelmia että robotteja ja esim. Tuomelan tutkimukseen verrattuna tuon kaksi uutta hakupalvelua vertailuun mukaan.
Tutkimuksessa kävi ilmi, että robottiohjelmien suunnittelussa on huomattavia eroja kuten myös hakuohjelmien toimivuudessa. Kokonaisuudessa hyödyllisimmältä hakupalvelulta tämän tutkimuksen perusteella vaikuttaa AltaVista, joka menee muiden edelle monipuolisuutensa ja vähien heikkouksiensa ansiosta. Hakuohjelmista InfoSeek kilpailee tasapäisesti AltaVistan kanssa, mutta sen robottiohjelma vaikuttaa heikosti suunnitellulta ja kuormittaa verkon muita palvelimia liian paljon. Vastaavasti roboteista HotBotin käyttämä ja Inktomin tekemä Slurp osoittautui ominaisuuksiltaan AltaVistan Scooterin veroiseksi. HotBotin hakuohjelmassa on kuitenkin puutteita.
2 Vertailussa mukana olleet hakupalvelut
Tutkimukseen mukaan otetut hakupalvelut ja näihin liittyvät robotit URL-osoitteineen on lueteltu liitteessä 1. Valituiksi tulivat ne palvelut, joiden robottiohjelma oli vieraillut tutkittavalla www-palvelimella tutkimuksen ajankohtana, 3.11.-12.12.1996. Näistä otettiin mukaan eniten sivuja hakeneet ja lisäksi myös muutama niistä suosituimmista hakupalveluista, joiden robotit eivät tutkittavalla palvelimella käyneet. Näin mukaan tuli seitsemän suurta hakupalvelua maailmalta sekä alan ainoa merkittävä suomalainen yrittäjä.
Tämän hetken hakupalveluista tunnetuin on Digitalin perustama AltaVista. Se on voittanut monta hakuohjelmien vertailua ja palkittukin alan parhaana useilla eri tahoilla. AltaVistan menestyksen salaisuus on pitkälti erittäin tehokas laitteisto. Lisäksi AltaVistassa on hyvin monipuoliset hakumahdollisuudet. Hakuja voi tehdä esim. jostain tietystä html-sivun kentästä tai hakea vaikkapa ainoastaan kuvia. AltaVistan tietokanta käsittää n. 30 miljoonaa html-sivua, jotka ilmeisesti on indeksoitu kokonaan päätellen suuresta löydettyjen dokumenttien määrästä eri hakusanoilla.
Excite on viime kuukausina kovasti uudistunut ja noussut hakupalveluiden parhaimmistoon. Sen tietokanta sisältää yli 50 miljoonaa täysin indeksoitua html-sivua ja hakuohjelmassa on ominaisuuksia, jotka pyrkivät tekemään hakuja käsitteen perusteella, ei pelkän hakusanan. Excitessa on myös "enemmän tällaisia" -ominaisuus, jonka avulla voi hakea lisää samantyyppisiä dokumentteja kuin jokin löydetyistä. Exciten huono puoli on heikko suunnittelu, sivut ovat varsin sekavat ja ensikertalaiselle vaikeat käyttää.
HotBot on Wired-lehden tuotteistama hakupalvelu, joka sisältää dokumentteja suurin piirtein yhtä paljon kuin Excitekin. Sivuilta ei kuitenkaan löydy, millä perusteella luku on saatu. Kuten Excite (1996) on esittänyt, dokumenttien määrän voi laskea ainakin kolmella eri perusteella ja nämä kaikki tuottavat täysin erilaisen luvun. HotBotin erikoisominaisuus on mahdollisuus tallettaa itselleen sopivat oletusarvot haussa käytettäville parametreille.
Tämän hetken ainoa laaja www-hakupalvelu suomessa on Piipää Oy:n tekemä Ihmemaa. Ihmemaa indeksoi vain suomalaisia www-sivuja ja siksi sen tietokanta on luonnollisesti selvästi pienempi kuin muiden tässä vertailussa olevien hakupalvelujen n. 330000 sivua. Ihmemaan haku osoittautui myös hitaimmaksi testatuista. Se löytää kuitenkin suomalaisia dokumentteja usein paremmin kuin muut hakukoneet ja on varsin selkeä sekä helppokäyttöinen. Ihmemaata käytettäessä kannattaa tehdä hakuja myös englanninkielisillä sanoilla, sillä näin löytyy yleensä jopa enemmän dokumentteja kuin suomenkielisillä sanoilla.
InfoSeek on jo pitkään ollut hakupalvelumarkkinoilla mukana ja on hiljattain julkistanut uuden UltraSeek-palvelunsa, jota tässäkin vertailussa käytettiin. UltraSeekin hakuohjelma muistuttaa paljon AltaVistaa ja myös siinä on erittäin laajat hakumahdollisuudet; on mahdollista hakea esim. linkkejä jollekin tietylle sivulle. Yksi UltraSeekin vahvuuksista on nopea haku pitkillä fraaseilla, esim. "to be or not to be". Tietokanta on samaa kokoluokkaa kuin Excitella eli yksi suurimmista.
Lycos oli ensimmäisiä kaupallistettuja www-hakupalveluita. Sittemmin aika ajoi siitä jonkin verran ohitse, mutta vuoden 1996 aikana Lycos on kovasti uudistunut. Tuloksena on erittäin monipuolinen hakujärjestelmä, joka kuitenkin on käyttäjän näkökulmasta hieman sekavakin. Lycos tuntee dokumentteja enemmän kuin mikään muu hakupalvelu n. 60 miljoonaa, mutta se indeksoi vain osan niiden sanoista, minkä vuoksi hakutulokset eivät ole yhtä hyvät kuin pahimmilla kilpailijoilla.
OpenText mainostaa itseään nopeimmaksi ja kattavimmaksi hakupalveluksi. Ainakin tämän tutkimuksen nopeustesteissä se hävisi kaikille muille suurille hakupalveluille ja tietokannan kokoa taas on vaikea verrata, sillä OpenText paljastaa vain tietokannassaan olevien sanojen määrän, joka on n. kymmenen miljardia. OpenTextin erikoisominaisuus on "Improve your results", jonka avulla käyttäjä voi lisäominaisuuksia hyväksi käyttäen tarkentaa hakua, joka on tuottanut huonon tuloksen. Tällä hetkellä OpenTextiin tehdään uudistuksia, joiden vuoksi sen robottikaan ei ollut tutkimuksen aikana liikkeellä.
WebCrawler oli ensimmäinen todellinen www-hakupalvelu ja kehitettiin Washingtonin yliopistossa. Sittemmin WebCrawlerkin on kaupallistettu, mutta silti sen tietokanta on pysynyt varsin pienenä. Kanta sisältää vain alle kaksi miljoonaa dokumenttia ja myös hakuominaisuuksia on varsin vähän. WebCrawler on kuitenkin nopea ja sen tekijät tarjoavat paljon mielenkiintoisia tietoja, joihin ovat palvelua kehittäessään törmänneet.
3 Vertailukriteerit ja niiden perusteet
Www-hakupalvelun kaksi tärkeintä osaa ovat hakurobotti, joka kerää tiedon, sekä hakuohjelma, jonka avulla tieto tarjotaan jalostetussa muodossa käyttäjälle. Kolmas oleellinen vaihe on näiden välissä oleva tietomassan indeksointi tavalla tai toisella.
Www-palvelun hyvyyttä voidaan mitata monin tavoin. Tässä tutkimuksessa valitsen useita kriteereitä niin hakurobotille kuin -ohjelmallekin ja vertailen eri palveluita sen suhteen, kuinka hyvin ne täyttävät nämä. Tekniikoina käytän Tampereen yliopiston www-palvelimen lokitiedostojen analysointia, itse tehtyjä hakupalvelujen koekäyttöjä sekä hakupalvelujen spesifikaatiodokumentteja. Yliopiston www-palvelin sopii tähän tarkoitukseen erinomaisen hyvin, sillä sitä käytetään paljon ja joka puolelta maailmaa (TaY 1996). Myös kymmenet hakurobotit vierailevat palvelimella säännöllisesti.
3.1 Robottien kriteerit
Www-palvelimen lokitiedostoja tutkimalla on mahdollista selvittää, millaisia jälkiä hakurobotit ovat vieraillessaan jättäneet. Tutkittavana oleva www-palvelin on konfiguroitu tallettamaan kaikki tarvittava tieto vasta 3.11.1996 lähtien, joten tämän tutkimuksen puitteissa ei ehditty tietoa saada kuin reilun kuukauden ajalta. Viimeinen päivä, joka tutkimukseen ehti mukaan, oli 12.12.1996. Näin ollen tutkittavia päiviä tuli yhteensä 41. Suurin osa roboteista ehtii tässä ajassa käydä päivittämässä tietokantansa tietyn palvelimen osalta, mutta esim. OpenTextin robotti ei käynyt kertaakaan tutkittavalla palvelimella tällä välillä.
Koster (1996) esittää lukuisia hakurobotin kriteerejä, joita voidaan tarkistaa www-palvelimen lokitiedostoista. Näitä ovat mm. :
- löytääkö robotti sellaisia dokumentteja, joita muut robotit eivät ole löytäneet; ei tämän tutkimuksen puitteissa järkevää tutkia, koska eri robotit ovat hakeneet aivan eri määrän dokumentteja
- identifioiko robotti itsensä käyttämällä http-protokollan User-agent -otsikkotietoa
- tarjoaako robotin kirjoittaja sähköpostiosoitteensa http-protokollan From-otsikkotiedossa
- kertooko robotti, mistä se tulee http-protokollan Referrer-otsikkotiedossa
- käyttääkö robotti http/1.1 -protokollan Accept-otsikkotietoa kertoakseen, minkä tyyppisiä dokumentteja se haluaa vastaanottaa tai pystyy vastaanottamaan
- käyttääkö robotti http-protokollan If-Modified-Since -otsikkotietoa tarkistaakseen, onko dokumentti muuttunut sitten viime vierailun
- tekeekö robotti hakuja palvelimelle harvakseltaan (esim. kerran minuutissa) niin, että palvelin ei kuormitu
- käyttääkö robotti HEAD-metodia verkon kaistanleveyden säästämiseksi silloin, kun se on mahdollista
- tarkistaako robotti hakemansa URLit vai hakeeko se myös linkit, jotka eivät johda mihinkään
- hakeeko robotti saman dokumentin vain kerran vai useammin
- käykö robotti sellaisena aikana, jolloin palvelimen käyttö on tavallista hiljaisempaa
- kuinka usein robotti käy uudistamassa tietokantansa
- noudattaako robotti /robots.txt-tiedostoa eli "Robots Exclusion Standard"ia
- tekeekö robotti tarpeettomia /robots.txt -tiedoston hakuja
Näiden lisäksi kriteereitä, joita voidaan tutkia muilla keinoin ovat ainakin seuraavat:
- jakaako robotti tiedot muille toisaalta raakana datana ja toisaalta jalostettuna vai ei ollenkaan
- onko robotti rekisteröitynyt eli kertonut maailmalle olemassaolostaan; listaa aktiivisista roboteista pitää yllä Koster (1996)
- onko mahdollista saada robotin kirjoittaja kiinni esim. finger- tai talk-protokollalla samalla hetkellä, kun robotti tekee hakujaan palvelimesta
- hakiko robotti sellaisia tiedostoja, joita se ei osannut käsitellä
3.2 Hakuohjelmien kriteerit
Hakuohjelman tehokkuutta ja muita ominaisuuksia on mahdollista mitata vain tekemällä hakuja eri palvelimista. Tämän tueksi voidaan hakea tietoja palvelujen julkisista spesifikaatiodokumenteista. On kuitenkin syytä muistaa, että ne ovat usein varsin subjektiivisia. Kriteereitä hyvälle hakuohjelmalle ovat esittäneet mm. Carl (1995), Barry (1996), Koch (1996) ja InfoSeek (1995). Näistä on tässä tutkimuksessa käytettäviksi valittu seuraavat:
- ohjelma kertoo, montako dokumenttia se sisältää ja millä perusteilla tämä luku on saatu, luku on myös helppo löytää
- mitä enemmän dokumentteja tietokanta sisältää, sitä parempi; muistettava kuitenkin että esim. pelkkä otsikko ei vielä ole kokonainen dokumentti, myös mahdolliset esim. alueelliset erikoistarkoitukset otettava huomioon
- hakustringi on helppo muodostaa, ohjelma on muutenkin mahdollisimman helppokäyttöinen ja selkeä
- ohjelmassa on hyvät, selkeät ja monipuoliset avustustoiminnot
- tietokanta sisältää dokumentteja mahdollisimman monelta palvelimelta ja palvelinten lukumäärä on esitetty
- ohjelma on nopea
- ohjelma ja palvelin sietävät kovankin kuormituksen; ei mitattavissa tämän tutkimuksen puitteissa
- hakuohjelmalla voidaan toteuttaa Boolen hakuja
- hakuohjelmalla voidaan toteuttaa monimutkaisiakin fraasihakuja, mitä nopeammin sitä parempi
- ohjelmalla on mahdollista hakea sanaa, jonka tarkka kirjoitusasu ei ole tiedossa
- ohjelma antaa yhteenvedon hakutuloksista, joissa kerrotaan mm. kuinka monta kertaa mikäkin hakusana täsmäsi
- ohjelma tulostaa kustakin löydetystä dokumentista yksittäisiä tietoja, mm. koska se on löydetty ja viimeksi toimivaksi havaittu
- parhaiten hakusanoja vastaavat hakutulokset tulostetaan ensimmäisinä
- ohjelma näyttää "sopivan" osan löydetystä dokumentista; ei liikaa eikä liian vähän
- tulokset esitetään selkeässä muodossa
- ohjelma huomaa sivut, joissa tiettyjä hakusanoja kymmenittäin lisäämällä on yritetty saada ne näkymään hakuohjelmissa ensimmäisenä
- ohjelma tarjoaa mahdollisimman vähän "kuolleita linkkejä", jotka eivät johda minnekään
- ohjelma löytää tietoja mahdollisimman monesta eri järjestelmästä (www, gopher, ftp, jne)
- ohjelma tarjoaa hakutuloksissa löydetyn dokumentin kirjoittajan yhteystiedot
- jos ohjelma ei löydä mitään, niin tulostetaan jonkinlainen vinkki käyttäjälle siitä, miten ohjelmaa pitäisi käyttää
- ohjelma sallii pienen kirjoitusvirheen; tämä on tosin vaikea toteuttaa mutta ainakin ohjelman pitäisi hakutuloksien yhteydessä kertoa, mitä hakusanaa käytettiin
- ohjelmalla on mahdollista tehdä near-tyyppinen haku, jossa haetaan sanoja, jotka esiintyvät dokumentissa lähellä toisiaan
- ohjelmassa on jokin erikoisominaisuus, jota ei muissa ole
- ohjelman yleisilme
4 Tulokset
4.1 Hakurobotit
Tauluun 1 on koottu hakurobottien vertailussa käytetyt kriteerit ja vertailussa mukana olleet robottiohjelmat. Ohjelmat on nimetty sen mukaan, mikä hakupalvelu käyttää kyseistä robottia. Ohjelmille on annettu pisteitä nollan ja kolmen väliltä sen mukaan, kuinka hyvin se minkäkin kriteerin täyttää. Hakukriteerit on numeroitu sen mukaan kuin ne kohdassa 3.1 esiteltiin. Pisteytys on varsin subjektiivinen enkä tässä esitä tarkkaan millä perusteilla on jossakin kohdassa saanut esim. yksi ja millä kaksi pistettä. OpenText on jäänyt vertailusta pois, koska sen robotti ei ollut aktiivinen tutkimuksen ajankohtana. Myös WebCrawler teki niin vähän hakuja, että sekin olisi ehkä ollut syytä jättää vertailusta pois. Selvästi eniten tutkimusaikana tekivät hakuja Ihmemaa, InfoSeek ja Excite. Näistä kaksi jälkimmäistä ovat säännöllisiä vierailijoita palvelimella, mutta Ihmemaan edellisestä visiitistä oli jo kulunut varsin pitkä aika.
| AltaVista | Excite | HotBot | Ihmemaa | InfoSeek | Lycos | OpenText | WebCrawler | |
| 1 | ||||||||
| 2 | ||||||||
| 3 | ||||||||
| 4 | ||||||||
| 5 | ||||||||
| 6 | ||||||||
| 7 | ||||||||
| 8 | ||||||||
| 9 | ||||||||
| 10 | ||||||||
| 11 | ||||||||
| 12 | ||||||||
| 13 | ||||||||
| 14 | ||||||||
| 15 | ||||||||
| 16 | ||||||||
| 17 | ||||||||
| 18 | ||||||||
| yht. |
Taulu 1. Hakurobottien vertailu.
Robottien käyttäytymisessä on yllättävänkin
suuria eroja. AltaVistan käyttämällä Scooterilla
on heikkoja kohtia kaikkein vähiten, mutta HotBotin Slurp
menestyi lähes yhtä hyvin. Suurin ero näiden kahden
välillä oli se, että Slurp kävi indeksoimassa
muutamia sellaisiakin tiedostoja, jotka /robots.txt -tiedostossa
eksplisiittisesti oli kielletty indeksoimasta. Vastaavasti InfoSeekin
robotti tuntuu varsin huonosti suunnitellulta ottaen huomioon
InfoSeekin suosion. Sen robotti teki pahimmillaan peräti
sata hakua minuutissa palvelimelle, mikä jo vaikuttaa palvelimen
toimintaa heikentävästi. Lisäksi joka kymmenes
InfoSeekin haku oli /robots.txt -tiedosto, mikä on noin 30
kertaa enemmän kuin useimmilla muilla. Lisäksi InfoSeek
tekee hakujaan pääasiassa juuri silloin, kun palvelin
on muutenkin ruuhkaisimmillaan. InfoSeekiäkin pienemmän
pisteluvun sai maineikas Lycos. Nämä ja muitakin tarkkoja
lukuja robottien vierailuista on esitetty taulussa 2.
| AltaVista | Excite | HotBot | Ihmemaa | InfoSeek | Lycos | WebCrawler | |
| hakuja | |||||||
| eri tiedostoja | |||||||
| robotx.txt -hakuja | |||||||
| eniten minuutissa | |||||||
| eniten päivässä | |||||||
| monenako eri päivänä | |||||||
| hakuja eniten klo | |||||||
| hakuja vähiten klo |
Taulu 2. Tilastoja hakurobottien vierailuista.
Taulu 1:ssä esitetystä vertailusta on syytä ottaa tarkemmin esiin joitakin seikkoja. Kohdassa 4 tutkittua Referrer-kenttää robotit käyttävät yllättävän vähän hyväkseen. Ihmemaa käytti sitä haettaessa /robots.txt -tiedostoa, mutta ei muulloin. Lisäksi HotBot käytti sitä säännöllisesti, mutta yhdisti sen From-kenttään, mikä voi aiheuttaa sekaannusta. Samoin kohdassa 6 tutkittu If-Modified-Since -kenttä oli vähän käytössä. Sitä käyttivät vain Ihmemaa sekä AltaVista ja nekin satunnaisesti.
Pahimmin kuormitusta palvelimella aiheutti InfoSeek. Myös Ihmemaa ja Lycos sortuivat välillä hakemaan dokumentteja liian kiivaaseen tahtiin. Kohdassa 8 tutkittua HEAD-metodia käytti vain Lycos, joka myös ainoana haki muitakin kuin tekstitiedostoja. Juuri näiden muiden tiedostojen hakemiseen Lycos käyttää HEAD-metodia. Kohta 9 jäi tutkimatta, koska kunnollinen testidokumentti jäi tutkimuksen alkuvaiheissa valitettavasti tekemättä. Kohdassa 10 huomattiin varsin suuria eroja siinä, kuinka monta kertaa robotit hakevat samoja tiedostoja uudestaan. Excite haki useita tiedostoja lähes 20 kertaa, kun taas Ihmemaa kävi hakemassa melkein jokaisen tiedoston vain kerran. Toisaalta Excite teki hakuja tasaisimmin, joka päivä jonkin verran. Muiden robottien haut kasautuivat enemmän tai vähemmän vain muutamille päiville. (kohta 12)
Kosterin (1996, Robots Exclusion Standard) laatimaa robottien poissulkemisstandardia kaikki pyrkivät noudattamaan, mutta Excite, HotBot ja Lycos hakivat siitä huolimatta muutamia kiellettyjäkin sivuja. Kaikki tutkitut robotit ovat rekisteröityneet, mutta Ihmemaan ja Lycosin tiedot rekisterissä ovat jo vanhentuneet. WebCrawler ei ainoana kerro yhteystietojaan lokitiedoissa ja muidenkaan tarjoamista osoitteista ei finger-protokollalla löytynyt mitään tietoa. Harmillinen ominaisuus lähes jokaisella robotilla oli se, että hakuja tehdään eniten päiväsaikaan, jolloin www-palvelimen käyttöaste on muutenkin korkeimmillaan.
4.2 Hakuohjelmat
Taulussa 3 on koottu vertailussa mukana olleet hakuohjelmat ja
käytetyt kriteerit. Kullekin palvelulle on annettu jokaista
kriteeriä kohti pisteitä nollasta kolmeen sen mukaan
kuinka hyvin se kyseisen kriteerin toteuttaa. Kriteerit on numeroitu
sen mukaan kuin ne kohdassa 3.2 esiteltiin. Kuten edellisessäkin
kohdassa, pisteytys on varsin subjektiivinen enkä tässä
esitä tarkkaan millä perusteilla on jostakin kriteeristä
saanut esim. yksi ja millä kaksi pistettä.
| AltaVista | Excite | HotBot | Ihmemaa | InfoSeek | Lycos | OpenText | WebCrawler | |
| a | ||||||||
| b | ||||||||
| c | ||||||||
| d | ||||||||
| e | ||||||||
| f | ||||||||
| g | ||||||||
| h | ||||||||
| i | ||||||||
| j | ||||||||
| k | ||||||||
| l | ||||||||
| m | ||||||||
| n | ||||||||
| o | ||||||||
| p | ||||||||
| q | ||||||||
| r | ||||||||
| s | ||||||||
| t | ||||||||
| u | ||||||||
| v | ||||||||
| w | ||||||||
| x | ||||||||
| yht. |
Taulu 3. Hakuohjelmien vertailu.
Lopputuloksiin on syytä suhtautua varauksella sen vuoksi, miten pisteytys on toteutettu. Tuskin kuitenkaan on sattuma, että palvelut joille annoin yleisilmeestä täydet pisteet, olivat myös kokonaispisteissä kaksi parasta. Suurin yllätys itselleni on OpenTextin ja WebCrawlerin korkeat pisteet. WebCrawler on pienestä tietokannastaan huolimatta muiden hyvien ominaisuuksien ansiosta varteenotettava palvelu sekin. OpenTextin harrastama itsensä kehuminen taas ei välttämättä ole aivan vailla perusteita.
On varsin suuria eroja siinä, kuinka avoimesti palvelut kertovat itsestään ja sisältämistään tiedoista. Useimmista toki löytyy ainakin muutaman minuutin haeskelun jälkeen luku, kuinka monta dokumenttia tietokanta sisältää. Mutta esim. Lycos ei missään kerro, kuinka luku on saatu vaikka tämä on hyvin oleellinen seikka. Tietokannan kokoa voi testata myös tekemällä erilaisia hakuja ja vertaamalla löytyneiden sivujen määriä. Näiden tietojen perusteella on saatu a- ja b-kohtien pisteet ja tässä mielessä kattavimmaksi osoittautui Excite.
Ohjelman helppokäyttöisyyttä tutkittiin kohdissa c ja d. Helppokäyttöisyyteen liittyy myös kohta t, jossa havaittiin melkoisia eroja. Excite, HotBot, Lycos ja WebCrawler eivät anna minkäänlaista vinkkiä käyttäjälle, jos haku ei tuota mitään tulosta. Sen sijaan InfoSeek ja OpenText tarjoutuvat auttamaan hakutulosten parantamisessa parhaiten. Nopeus taas käsiteltiin kohdassa f ja testattiin mittaamalla hakuaika kuudella eri tyyppisellä hakustringillä. Testi ei luonnollisesti ole absoluuttisen tarkka johtuen verkon kuormituksen eroista, mutta suuntaa-antava kuitenkin. Myös tässä mielessä Excite osoittautui WebCrawlerin ja AltaVistan ohella yhdeksi parhaista; se ei tosin tehnyt yhtään hakua erityisen nopeasti, mutta toisaalta mikään ei myöskään vienyt kovin kauan.
Hakulöydökset, jotka eivät johtaneet mihinkään (kohta q), testattiin antamalla hakusanaksi "computer science" ja tutkimalla kymmenestä ensimmäisestä löydöksestä, kuinka moni ei ollut olemassa. Tässä muita heikompana erottui Lycos, jolla oli peräti kolme ns. kuollutta linkkiä kymmenestä. Kirjoitusvirheitä ei sallinut yksikään ohjelma, mutta hankalinta tämä oli niiden kohdalla, jotka eivät hakutulosten yhteydessä kerro, millä hakusanalla haettiin. Tällöin kirjoitusvirheen tehneen käyttäjän on hyvin vaikea huomata erheensä.
4.3 Yhteistulokset
Vaikka toisaalla tässä raportissa esitetyistä syistä johtuen tutkimuksen lopputulokset eivät ole mikään yksikäsitteinen totuus, esitän silti taulussa 4 hakuohjelmien ja -robottien vertailun yhdistetyt tulokset. Palvelut on järjestetty yhteispisteiden mukaan, mutta erikseen on esitetty niin hakurobotin kuin -ohjelmankin saamat pisteet. OpenTextin robottia ei ollut tällä ajanjaksolla mahdollista tutkia, joten siitä esitetään vain hakuohjelman saamat pisteet. OpenTextin hakurobotin mahdollista pistemäärää ei tämän perusteella voi edes arvioida.
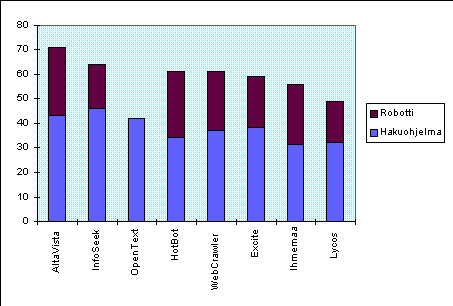
Taulu 4. Vertailun lopputulokset.
Pahimmat ja tavallisimmat virheet, joita hakurobottiohjelmat näyttävät
tekevän ja joita olisi syytä välttää,
ovat:
Vastaavasti virheitä, joita hakuohjelmien tekijöiden
pitäisi välttää, mutta joita silti ohjelmissa
esiintyy, ovat:
Paras hakuohjelman ja -robotin yhdistelmä on se, joka välttää
parhaiten yllämainitut virheet ja jolla on lisäksi toimivia,
persoonallisia ominaisuuksia niin paljon että palvelu erottuu
kilpailijoista. Näkyvimpiä virheitä ovat hakuohjelmassa
olevat, mutta robottiohjelman virheet saattavat pitemmällä
aikavälillä tuottaa tekijälleen huonoa mainetta.
Vaikka AltaVista tässäkin tutkimuksessa todettiin ainakin
jossain mielessä muita hyödyllisemmäksi ja paremmin
toteutetuksi palveluksi, kannattaa käyttäjän silti
opetella ja totutella käyttämään useita hakuohjelmia.
Ne kaikki löytävät kuitenkin eri sivuja ja toimivat
eri perusteilla. Taulussa 4 esitettyjä tuloksia ei myöskään
ole syytä pitää hakupalvelujen absoluuttisena paremmuusjärjestyksenä
eikä sellaista edes ole olemassa.
Suurin hankaluus tämän tyyppisessä tutkimuksessa
on saada mahdollisimman objektiiviset kriteerit palveluita vertailtaessa
ja suhteuttaa ne oikein. Tässä valitsin helpon tien
ja pisteytin kaikki kriteerit nollasta kolmeen tarkentamatta eri
pistemäärien ehtoja sen kummemmin. Parempiin tuloksiin
pääsemiseksi pitäisi pohtia ja tutkia tarkemmin,
mitkä kriteerit ovat tärkeimpiä ja mitkä vähemmän
tärkeitä. Myös eri pistemäärille pitäisi
laatia yksikäsitteiset ehdot, joiden perusteella ei jäisi
epäselväksi, miksi mikäkin palvelu on saanut minkäkin
pistemäärän. Tässä käytetty tapa
on kuitenkin myös ainakin suuntaa-antava ja toivottavasti
hyödyllinen lukijalle. Voidaan myös kysyä, onko
järkevää mitata hakupalveluja pistein. Itse katson
tämän kelvolliseksi lähestymistavaksi, koska useimmat
hakupalvelut kuitenkin pyrkivät jokseenkin samaan lopputulokseen.
Yksi suurimmista hakurobottien ongelmista on se, että ne
ruuhkauttavat jo muutenkin vilkasta verkkoliikennettä internetissä.
Useimmat robotit pyrkivät pienentämään aiheuttamansa
haitan tekemällä hakuja harvaan tahtiin, mutta kenenkään
ei ole pakko tehdä näin. Eikä tuo edes ole mikään
ratkaisu, kun verkossa on kuitenkin satoja robotteja, jotka tekevät
kukin miljoonia hakuja päivässä.
Yksi mahdollinen ratkaisu verkon kaistan kulutusongelmaan voisi
olla mm. Grahamin (1996) ja InfoSeekin (1996) esittämä
tapa. Kumpikin on tosin hieman erilainen, mutta perusajatuksena
on molemmissa se, että www-palvelimen ylläpitäjä
tekee osan työstä roboteille valmiiksi. Hän voisi
esim. tehdä tietyn standarin mukaisen tiedoston, jossa esitetään
kaikki palvelimen dokumentit ja niiden viimeinen päivitysaika.
Tämä tiedosto sijoitettaisiin palvelimen juurihakemistoon
ja näin hakurobotin ei tarvitsisi hakea kuin tämä
yksi dokumentti tuolta palvelimelta.
Toinen ongelma tämän hetken roboteissa on se, että
monet www-sivut muuttuvat jatkuvasti ja lisäksi suuri osa
sivuista luodaan dynaamisesti käyttäjän syötteen
perusteella. Tällaisia sivuja hakurobotit joko eivät
löydä tai sitten löytävät sellaista,
mitä ei enää ole olemassa, kun loppukäyttäjä
tekee hakuaan.
Kolmas lähitulevaisuudessa oleva muutossuuntaus hakuroboteissa
on http-protokollan uusi 1.1-versio (Fielding et al. 1997). Uusi
versio tuo mukanaan runsaasti uusia ominaisuuksia, joita myös
robotit voivat käyttää hyväkseen. Myös
robottien torjumiseen käytettyä ollaan uudistamassa
ja Kosterin (1996) lisäksi uusia ominaisuuksia on esittänyt
mm. Frumkin (1996).
Barry, Tony, Joanna Richardson (1996). "Indexing the Net A Review
of Indexing Tools." [http://bond.edu.au/Bond/Library/People/jpr/ausweb96/].
Päivitetty: 7/1996, tarkistettu: 12/1996.
Berners-Lee, Tim, Robert Cailliau, Ari Luotonen, Henrik Frystyk
Nielsen, Arthur Secret (1994). "The World-Wide Web." Communications
of the ACM, v. 37, n. 8, August 1994, pp. 76-82.
Berners-Lee, Tim, R. Fielding, F. Nielsen (1996). "HyperText Transfer
Protocol." Request For Comments 1945. [ftp://ds.internic.net/rfc/rfc1945.txt].
Päivitetty: 5/1996, tarkistettu: 12/1996.
Bray Tim (1996). "Measuring the Web." Proceedings of the fifth
World-Wide Web International Conference, Paris France. [http://www5conf.inria.fr/fich_html/papers/P9/Overview.html].
Päivitetty: 4/1996, tarkistettu: 12/1996.
Cailliau, Robert (1995). "A Little History of the World Wide Web."
[http://www.w3.org/pub/WWW/History.html]. Päivitetty: 10/1995,
tarkistettu: 12/1996.
Carl, Jeremy (1995). "Protocol Gives Sites Way To Keep Out The 'Bots."
Web Week, Volume 1, Issue 7, November 1995 » Mecklermedia
Corp. [http://www.webweek.com/95Nov/news/nobots.html]. Päivitetty:
11/1995, tarkistettu: 12/1996.
De Bra, P.M.E, R.D.J. Post (1994). "Information Retrieval in the
World-Wide Web: Making Client-based searching feasable."
Proceedings of the First International World-Wide Web Conference,
Geneva Switzerland. [http://www.cern.ch/PapersWWW94/reinpost.ps].
Päivitetty: 5/1994, tarkistettu: 11/1996.
Excite Inc (1996). "How to count URLs." [http://www.excite.com/ice/counting.html].
Päivitetty: 1996, tarkistettu: 12/1996.
Fielding, R, J. Getty, J.C. Mogul, H. Frystyk, T. Berners-Lee (1997).
"
Hypertext Transfer Protocol -- HTTP/1.1.
" Request For Comments 2068.
[http://www.w3.org/pub/WWW/Protocols/rfc2068/rfc2068.txt].
Päivitetty 1/1997, tarkistettu 1/1997.
Frumkin, Mike, Graham Spencer (1996). "Additions to the robots.txt
standard." [http://www.w3.org/pub/WWW/Search/9605-Indexing-Workshop/Papers/Frumkin@Excite.html].
Päivitetty 6/1996, tarkistettu 12/1996.
Graham, Ian (1996). "Server Resource Database Interface." [http://www.utoronto.ca/ian/docs/Indexing/server.html].
Päivitetty ja tarkistettu: 12/1996.
Gray, Matthew (1996). "Internet Statistics." Growth and Usage
of the Web and the Internet. [http://www.mit.edu/people/mkgray/net/].
Päivitetty: 6/1996, tarkistettu: 12/1996.
InfoSeek Corporation (1995). "Comparison of World Wide Web Search
Engines." [http://ultra.infoseek.com/doc?pg=comparison.html&sv=US&lk=1].
Päivitetty: 1995, tarkistettu: 12/1996.
InfoSeek Corporation (1996). "sitelist.txt." [http://topgun.infoseek.com/stk/papers/sitelist.html].
Päivitetty: 8/1996, tarkistettu: 12/1996.
Jian Liu (1996). "Understanding WWW Search Tools." [http://www.indiana.edu/~librcsd/search/].
Päivitetty: 9/1996, tarkistettu: 12/1996.
Koch, Traugott (1996). "Internet search services." [http://www.ub2.lu.se/tk/demos/DO9603-meng.html].
Päivitetty: 3/1996, tarkistettu: 12/1996.
Koster, Martijn (1996). "World-Wide Web robots, wanderers and spiders."
[http://info.webcrawler.com/mak/projects/robots/robots.html].
Päivitetty: 1996, tarkistettu: 12/1996.
Lottor, Mark (1996). "Number of Internet hosts." [http://www.nw.com/zone/host-count-history].
Päivitetty: 9/1996, tarkistettu: 15.12.1996.
Naples Internet Marketing Services (1996). "The Spot for All Bots
on the Net." [http://www.botspot.com/]. Päivitetty ja
tarkistettu: 12/1996.
Raggett, Dave (1996). "HTML 3.2 Reference Specification." [http://www.w3.org/pub/WWW/TR/PR-html32-961105.html].
Päivitetty: 11/1996, tarkistettu: 12/1996.
Rissa & Järvinen Oy (1996). "Toinen suomalainen Internet-käyttäjätutkimus."
[http://www.pjoy.fi/tutkimus/kt96/tulokset.htm]. Päivitetty:
2/1996, tarkistettu: 12/1996.
Tampereen yliopisto (1996). "Web server statistics for www.uta.fi."
[http://www.uta.fi/stats/www/analog.html]. Päivitetty ja
tarkistettu: 12/1996.
Tuomela, Sanna (1996). "Hakukoneiden arviointi." [http://www.oulu.fi/library/johdanto.htm].
Päivitetty: 8/1996, tarkistettu: 12/1996.
5 Johtopäätöksia, keskustelua
6 Yhteenveto
VIITELUETTELO
Liite 1. Tutkitut hakupalvelut
| Palvelu | URL (http://...) | Robotin nimi | Tietoa robotista (http://...) |
| AltaVista | www.altavista.digital.com | Scooter | scooter.pa-x.dec.com |
| Excite | www.excite.com | ArchitextSpider | www.atext.com/spider.html |
| HotBot | www.hotbot.com | Slurp | www.inktomi.com/slurp.html |
| Ihmemaa | www.fi | Hämähäkki | www.fi/hakuinfo.html |
| InfoSeek (UltraSeek) | www.infoseek.com | InfoSeek Sidewinder | - |
| Lycos | www.lycos.com | Lycos_Spider | - |
| OpenText | index.opentext.net | OTI_Robot | index.opentext.net/OTI_Robot.html |
| WebCrawler | webcrawler.com | WebCrawler | webcrawler.com/WebCrawler/Facts/HowItWorks.html |